ai for science,憧憬一个人人都可参与科学发现的未来
2024-05-16 | 作者:刘铁岩
编者按:正处于起步阶段的 ai for science 被认为是科学发现的第五范式。尽管目前对于 ai for science 的定义和研究方向仍有诸多讨论,但这并不妨碍 ai for science 已经开始在科学发现的实践中取得令人瞩目的成果。近年来,微软研究院科学智能中心杰出首席科学家刘铁岩博士和他的团队致力于推动 ai for science 的发展和应用。在这篇署名文章中,刘铁岩博士将分享他对人工智能在科学领域关键研究方向的看法 ,以及对 ai for science 未来前景的展望。

“ai for science 预示着一种全新的科学发现范式。通过构建统一的科学基座模型,ai for science 将消除不同科学领域之间的壁垒,实现通过一个模型解决众多科学难题的目标。它还有望推动更加普及的科学探索范式,通过与基座模型交互,让每个人都能参与到科学发现的过程中。而为了实现这些愿景,我们必须要让科学基座模型超越人类语言的限制,去学习、理解大自然的语言。”
——刘铁岩,微软研究院科学智能中心杰出首席科学家
今天的人工智能技术,在很多任务上的表现已经可以媲美人类,特别是在认知、感知等层面。然而,我们对人工智能的长远愿景决不能局限在复刻人类已有的知识和技能——我们更期待人工智能可以帮助人类探索未知领域,加速我们认识世界和改造世界的进程。
科学进步是推动现代人类社会发展的核心动力。因此,赋予人工智能以科学发现的能力,无疑是其发展的必然方向之一。图灵奖获得者 jim gray 在《科学发现的四个范式》一书中将科学发现的历程分为四个阶段:千年前的经验科学、百年前的理论科学、几十年前的计算科学,以及十几年前的数据科学。而 ai for science 的出现将会成为前四种范式的有机结合和升华,我们称之为科学发现的“第五范式”,并不吝寄予其更大的期望。
2022年,微软研究院成立了科学智能中心(microsoft research ai for science),我有幸作为该团队的创始成员之一,与世界各地的顶尖专家共同探索这一跨领域研究的开创性课题。经过两年的努力,我们在 ai for science 的研究上取得了一系列令人振奋的成果。更重要的是,这一过程也在不断刷新我们对 ai for science 的理解。
我想分享的一个深刻的感受:我们必须正视科学发现的艰巨性。我们决不能简单地认为只要高举 ai 的大锤,就可以轻易攻克科学发现的难题。ai for science 的健康发展,需要我们秉承格外严谨和审慎的态度,始终对科学发现保持敬畏之心,在深入理解科学规律的基础上,对现有的 ai 工具进行改造、甚至发明全新的 ai 理论和算法。只有这样,才有可能让 ai 真正加速科学发现的进程,改变科学发现的格局。
ai for science的三个要素
作为一个新兴领域,ai for science 尚未有一个公认的定义。在我看来, ai for science 并不等于“在科学研究过程中使用一些 ai 技术”。我们所追求的 ai for science 是一个更加系统和深入的概念,ai 要深度融入科学研究的各个环节,从数据处理到仿真模拟,到实验研究,到发现新的科学规律,ai 要成为科学研究的核心技术,要为科学发现雪中送炭,而不是锦上添花。
我认为,ai for science 应该包含三个要素:利用合成数据、构建科学基座模型、实现科学研究的闭环。
利用合成数据:在自然科学领域,有很多科学规律可以指导我们利用计算的方法产生合成数据,比如通过求解薛定谔方程获得电子结构和分子体系的微观属性,通过求解纳维斯托克斯方程获得流体的速度和压力场。而这些合成数据不受实验条件的局限,只要有足够的计算资源就可以产生任意多的数据。通过这些合成数据训练出来的人工智能模型,可以实现对这些科学方程更加直接且高效的求解,进而用于生成更多的合成数据。这种合成数据的飞轮效应,能够让人工智能模型实现自我演化,更快、更有效地学习和提高自身能力,从而更深入地理解科学的本质,拓展科学的边界。
构建科学基座模型:ai for science 应当遵循类似 gpt 等大模型的设计思路,用一种通用技术来解决广泛的科学问题。在过去的科学研究中,人们通常认为隔行如隔山,不同领域的科学问题需要用独立的方法来求解。但是,我们的客观世界实际上是由一些“简单通用”的底层规律所支配的。比如,无论是不规则的无机小分子、周期性的晶体材料、还是蛋白质、dna 等生物大分子,其背后都被薛定谔方程所支配着。这种科学规律的共通性为我们整合所有科学领域、任务、和模态,构建统一的科学基座模型奠定了基础。科学基座模型可以帮助我们找到复杂现象背后的规律和内在联系,在不同学科知识的碰撞中产生“1 1>2”的效果,从方法论层面影响科学发现。此外,科学基座模型还要从各种科学文献中学习人类历史上积累的科学知识及其推理能力,并在此基础上实现人类语言和科学语言的衔接,使普通人也能通过语言与基座模型交互,从而降低科学发现的专业门槛,让人人都能成为“爱因斯坦”,推动科学发现的“平权”。
实现科学研究的闭环:科学发现是一个大胆假说、小心求证的过程,后者通常依赖于实验室工作。为了实现科学发现的全链条,ai for science 必须与真实世界形成闭环,不能仅仅局限于数字世界。近年来,实验室自动化已成为科学探索的新趋势,人工智能是这些自动化实验室的大脑,指导机械臂精确执行操作,自动合成、自动实验,从而实现从理论到实验验证的完整闭环。试想一下,一旦我们可以利用科学基座模型提出新的科学假说、进行计算仿真、再通过自动化实验室来验证,并将结果反馈给基座模型修正假说、反复迭代——以上过程能够7×24小时全天候运行,人类的科学发现能力将发生根本性的改变。
ai for science的基座模型要读懂大自然的语言
微软研究院科学智能中心自成立之初,就将科学基座模型作为主要的研究项目,并且明确了科学基座模型的发展方向——科学基座模型必须要突破人类语言的局限,要能够学习和理解科学概念、科学实体、科学规律,掌握支配万事万物的大自然的语言。
目前,市面上的科学大模型可以分为两个类别,一类是针对特定的垂直子领域,如蛋白质、dna、单细胞等,设计和训练相应的大模型;另一类是将 gpt 等大语言模型进行改造或者适配到科学领域。前者只见树木,不见森林,聚焦在一个小的垂直领域,无法学到普遍的科学规律,离掌握大自然的语言相去甚远;后者则对人类语言过度依赖,作为一种基于统计的、线性、符号化的表达方式,人类语言难以完整地描述自然界的多样性和复杂性。
大自然语言是一种高维度、多模态、科学严谨的表达。首先,自然界中的物质世界是高维度、多尺度的,不同维度和尺度之间受到深层科学规律的相互制约,这些规律无法简单地用人类语言的字符序列加以表达。其次,自然界里存在各种不同的模态,比如复杂的声光电现象、波粒二象性、时空的相互转化等等,蕴含着用人类语言无法充分描述的深刻奥秘。再有,人类语言会受到个体认知和社会文化等因素的影响,存在偏倚和误差。而科学探索追求的是严谨及普适性,大自然的语言是客观存在且不受人为因素影响的。我们只有构建能够处理高维、多模态数据的科学基座模型,并将科学规律巧妙地融入模型的构建和训练过程中,才能外推到模型未曾见过的客观世界,才能真正学习和掌握大自然的语言。
聚焦微观世界的深入探索与应用
面向微观世界和宏观世界的研究是 ai for science 的两个重要方向。由于微观世界的科学规律已经被人类充分掌握,理论完备,也有很多直接或间接的实验手段,因此 ai for science 在微观领域大展身手具有充分的理论和实践基础。针对宏观世界,虽然人类还没有完全掌握其背后的物理规律,但也已经积累了大量数据,ai for science 可以利用这些数据,进行规律挖掘和预测,如天气预报和气候变化研究等。
目前,微软研究院科学智能中心的 ai for science 研究更专注于微观世界,并将相关的研究项目分成了三个层次:基础层是科学基座模型;中间层是科学仿真工具(如电子结构预测、分子动力学模拟等);应用层是解决各领域的重大科学问题(如材料设计和药物开发等)。
在基础层,我们致力于设计和训练科学基座模型。经过近两年的深入研究,我们已经取得了一些突破性进展,开发出了基座模型的一些重要子模块,在分子科学的关键领域展示出令人振奋的能力。例如,我们在 neurips 上发表的 graphormer 模型,是科学基座模型的结构编码器,它对分子结构的理解有非常独到的能力,在第一届 ogb-lsc 分子建模比赛和 oc20 催化剂设计开放挑战赛中都力压群雄,获得冠军;我们开发的 biogpt 模型,作为科学基座模型的序列解码器的一部分,是第一个在 pubmed qa 任务上超过人类专家水平的 ai 模型;而我们刚刚在《自然-机器智能》(nature machine intelligence)杂志上发表的用于分子结构平衡分布预测的深度学习框架 distributional graphormer,则是科学基座模型的结构解码器,它能够对分子的动态统计特性进行端到端的建模,在物质的微观分子结构和宏观物化属性之间建立了连接的桥梁。
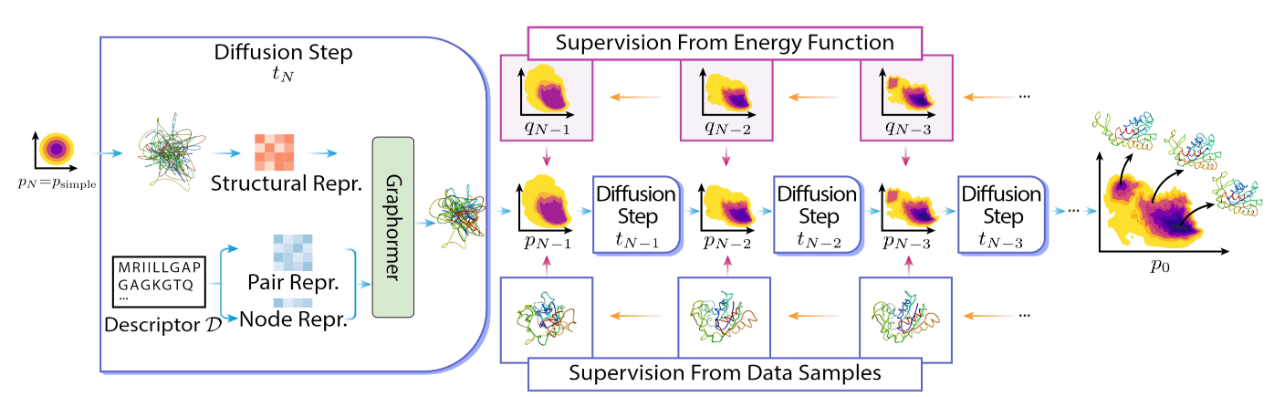
distributional graphormer 示意图
在中间层,我们的研究重点包括电子结构预测、分子动力学模拟等,这些方向为理解和预测分子行为提供关键信息。在电子结构预测方面,我们在《自然-计算科学》(nature computational science) 杂志上发表了 m-ofdft 技术,可以利用 ai 方法将传统 dft(密度泛函理论)的复杂度明显降低 。同时,我们还在 gpu 加速、并行计算等方面进行了更加深入的探索,进一步提高dft的计算效率,成功将dft计算拓展到更大尺度的分子体系,该技术已在微软 azure 云平台上发布。在分子动力学模拟方面,我们开发了机器学习力场 visnet,它可以针对蛋白质等生物大分子给出精准的能量和力场的预测,相关研究成果作为编辑精选文章发表在《自然-通讯》(nature communications)杂志上,并且获得了首届全球 ai 药物设计大赛的冠军。
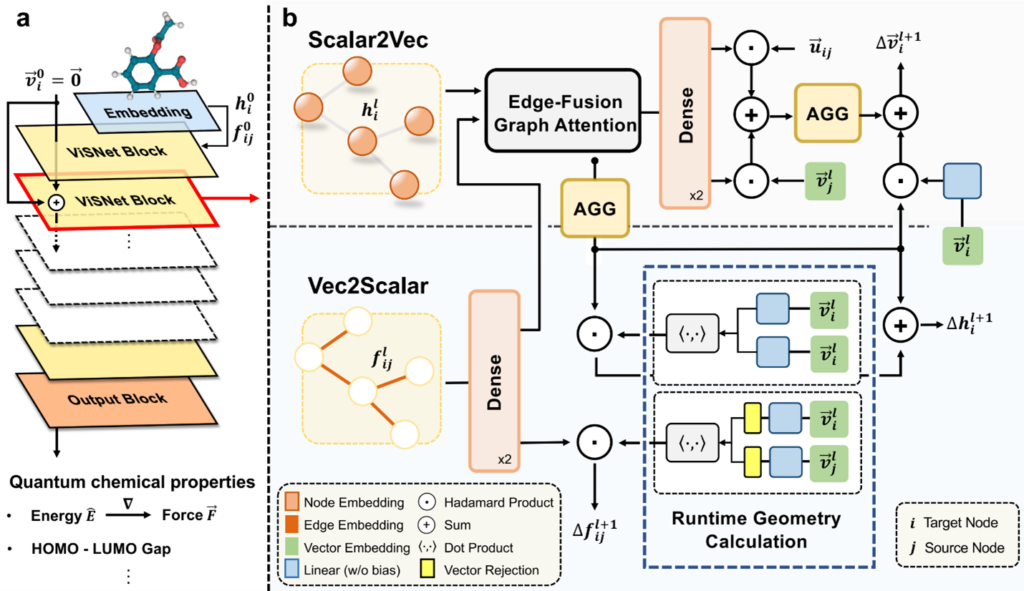
visnet 示意图
中间层的 ai 模型和科学基座模型有着很强的依赖关系,它们会在科学基座模型的通用建模能力的基础上,再融入领域数据和洞察,通过模型微调或知识蒸馏,获得针对特定领域更高的精度或更高的效率。
在应用层,我们特别关注制药和材料领域的重大科学问题。这是当前与 ai for science 研究最契合,而且市场需求最大的领域。在此方向上我们也取得了令人鼓舞的成果,比如能够加速发现和设计更新颖、更稳定材料的 mattersim 和 mattergen 模型;能够根据指定靶点,自动设计候选药物的 tamgen 模型。尤其是基于 tamgen 模型,我们与 ghddi(全球健康药物研发中心)和盖茨基金会进行了深入合作,为肺结核和冠状病毒等仍然肆虐全球的传染病设计出了全新的高效候选药物,经过实验室合成和酶抑制试验,这些 ai 设计出来的候选药物表现出了非常优异的性能,与已知的先导化合物相比,其生物活性提高了近10倍,为治愈相关疾病做出了有益的探索。除此之外,我们也在研究科学智能体和关注实验室自动化,希望能够早日实现科学发现的自动化,助力人类文明以更快的节奏进化。我们还十分关注负责任的 ai for science,利用法律、道德和社会规范为 ai for science 的研究保驾护航。
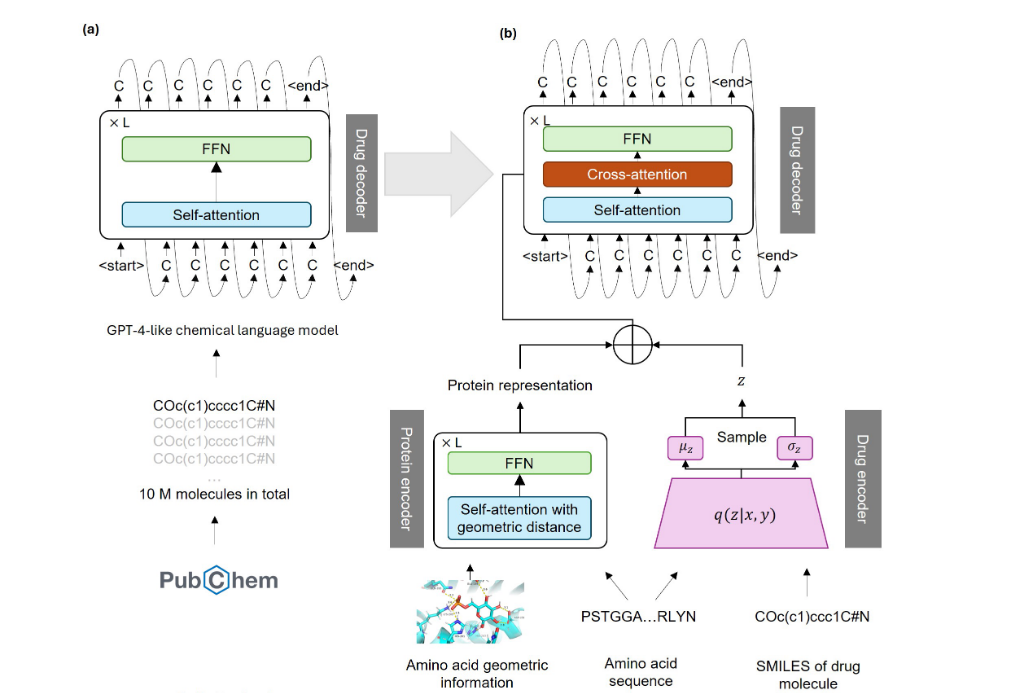
tamgen 示意图
憧憬人人都可参与科学发现的未来
ai for science 的深入研究与发展,将为科学发现打开无限可能,为人类探索自然提供更丰富的方法和工具。利用 ai for science,计算机模拟的精度将无限接近于现实世界实验的精度,助力科学研究的质量和效率提升至全新高度,引领科学探索进入崭新的阶段。
更重要的是,科学基座模型的引入有望使科学发现变得更加普及化。科学探索将不再仅仅是专业领域科学家们的“特权”,任何对科学发现抱有热情的人,都将能够通过语言与大模型进行交互,验证他们的奇思妙想。这将激励更多人参与解决诸如医疗健康、新材料发现、可持续发展等社会性问题,前所未有地汇聚全人类的智慧来造福世界。
当然,我们也必须清醒地认识到,ai for science 的发展并非一蹴而就,需要长期的投入和研究,并攻克一些前所未有的挑战。作为一个高度跨学科的研究领域,ai for science 对交叉领域人才的需求非常迫切。ai for science 的研究者需要在计算机或自然科学领域具有很深的造诣,并且对交叉学科相互融合具备广阔的视野和开放的心态,对其他领域的难度和复杂性保持充分的理解与尊重。
算力和数据同样给 ai for science 研究带来了极大的挑战。自然科学现象的数据类型和复杂度都远超语言数据,深入研究科学智能所需的算力和数据量也将呈指数级增长,大大高于现有的大语言模型。
此外,构建完整的 ai for science 研究闭环并非易事。正如之前提到的,研究闭环不仅关系到验证假说的有效性,也是衡量人工智能在科学发现中的效率和质量的关键。但传统的实验室方法论难以支持 ai for science 的发展,我们需要全新的实践方法论,例如设计全新的实验方案和自动化流程。
尽管 ai for science 作为新兴的科学发现范式还面临着许多未知的挑战,但我们目前所取得的每一点进展都预示着它将为人类带来无尽的可能性。ai for science 研究中不乏令人望而却步的难题,但也正是这些难题,激发了我们探索和创新的热情。我和我的同事们将继续怀揣着极大的热忱投身于这一领域,并乐于与那些对 ai for science 秉持严谨态度和长远愿景的各领域专家学者合作,共同推动 ai for science 成为人类认识世界和改造世界的变革性力量。
本文作者
刘铁岩博士,微软杰出首席科学家、微软研究院科学智能中心亚洲区负责人。他是国际电气电子工程师学会(ieee)会士、国际计算机学会(acm)会士、亚太人工智能学会(aaia)会士。他(曾)被聘为卡内基梅隆大学、清华大学、香港科技大学、中国科技大学、南开大学、华中科技大学兼职教授、诺丁汉大学荣誉教授。
刘铁岩博士的先锋性研究促进了机器学习与信息检索之间的融合,被公认为“排序学习”领域的代表人物。近年来他在深度学习、强化学习、工业智能、科学智能等方面颇有建树,在顶级国际会议和期刊上发表论文数百篇,被引用数万次。他曾担任 www/webconf、sigir、neurips、iclr、icml、ijcai、aaai、kdd 等十余个国际顶级学术会议的大会主席、程序委员会主席或(资深)领域主席;包括 acm tois、acm tweb、ieee tpami 在内的知名国际期刊副主编。
刘铁岩博士毕业于清华大学,先后获得电子工程系学士、硕士及博士学位。
相关链接:
